Covid-19 : une modélisation simple utilisant Excel, accessible aux non-mathématiciens et pleine d’enseignements

Les équations différentielles établies par Kermack et McKendrick en 1927 permettent de modéliser le développement d’une épidémie. Malgré leur simplicité, elles n’ont pas de solution pouvant être exprimée sous forme analytique. Quant aux multiples modèles dérivés, de plus en plus complexes sur le plan mathématique, leurs prévisions n’ont pas toujours été fiables. Or l’emploi d’Excel n’est pratiquement jamais évoqué dans les cours d’épidémiologie, alors qu’il permet de rendre la modélisation d’une épidémie compréhensible à des non-mathématiciens, de leur de montrer sa pertinence et de leur faire comprendre quelles sont les futures évolutions possibles.
Pour le non-mathématicien, tirer personnellement des enseignements pratiques du modèle épidémiologique de Kermack et McKendrick, même sous sa forme la plus simple dite SIR, paraît très ardu : les spécialistes lui parlent d’exponentielles, de dérivées, d’équations différentielles non linéaires impossibles à résoudre sans recourir à des solveurs informatiques. Le résultat est une prise de distance fréquente vis-à-vis de cette discipline de la part de beaucoup de médecins, qui va pour certains jusqu’à l’affirmation qu’elle n’est pas plus crédible que l’astrologie.
Le modèle SIR
Rappelons que dans ce modèle la population composée de N individus est divisée en 3 « compartiments » :
- S population saine non contaminée ;
- I population infectée réputée contagieuse ;
- R population « remise » c’est-à-dire guérie et réputée immunisée, ou décédée.
Exprimées en langage de non-mathématiciens utilisateurs d’Excel, les équations de Kermack et McKendrick signifient que :
- La population S (au départ égale à N moins quelques individus infectés) diminue quotidiennement de β.S.I individus (β est égal à R0 /(N.D), R0 étant le « taux de reproduction initial » souvent évoqué par les médias et D la durée moyenne pondérée en jours d’infection avant guérison ou décès).
Bien noter que la notation traditionnelle R0 n’a rien à voir avec R à l’instant 0.
- La population R (au départ nulle) augmente quotidiennement de γ.I individus (γ étant l’inverse de D).
- La population I (au départ quelques individus) est la différence entre N et (S + R).
Nota : paraîtrait plus logique une modélisation où, au lieu de γ.I individus entrant le jour J dans le compartiment R, y basculeraient ceux qui ont quitté le jour (J‑D) le compartiment S. Néanmoins les équations classiques de Kermack et McKendrick présentent l’avantage d’avoir fait depuis 1927 l’objet de nombreuses études qui ont fourni un certain nombre de conclusions validées par l’observation de cas concrets d’épidémie. Une comparaison entre des modélisations Excel fondées sur les deux types d’équations n’a pas montré de différence affectant de façon fondamentale les résultats exposés dans cet article, qui est donc basé sur l’utilisation des équations traditionnelles.
Où Excel excelle
À partir de D, N et R0 il est facile de bâtir un tableau Excel donnant l’évolution de S, I et R et de leurs variations quotidiennes pendant quelques centaines de jours. L’avantage sur des méthodes mathématiques classiques est l’extrême souplesse avec laquelle ce logiciel permet d’introduire des données d’entrée suivant n’importe quelle évolution au cours du temps, en particulier pour R0 (et par voie de conséquence β).
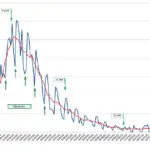
Le diagramme suivant montre l’évolution de I et de R au début d’une épidémie qui, dans le cadre de vie habituel d’un pays de 67 millions d’habitants, présente un R0 de 3. Le 17 mars le nombre de nouveaux infectés quotidiens atteint 100 000, ce qui risque d’entraîner 20 jours plus tard un nombre de décès quotidien de 500 à 1 000, compte tenu d’une létalité réelle de 0,5 à 1 % (voir plus loin). Les pouvoirs publics décrètent alors un confinement général qui fait baisser immédiatement R0 à 0,7 pendant 55 jours. Après le déconfinement du 11 mai, en particulier sous l’influence de mouvements libertaires niant la persistance de l’épidémie, R0 remonte progressivement de façon linéaire jusqu’à 1,3 en 4 mois, puis se stabilise à ce niveau à partir de septembre 2020.
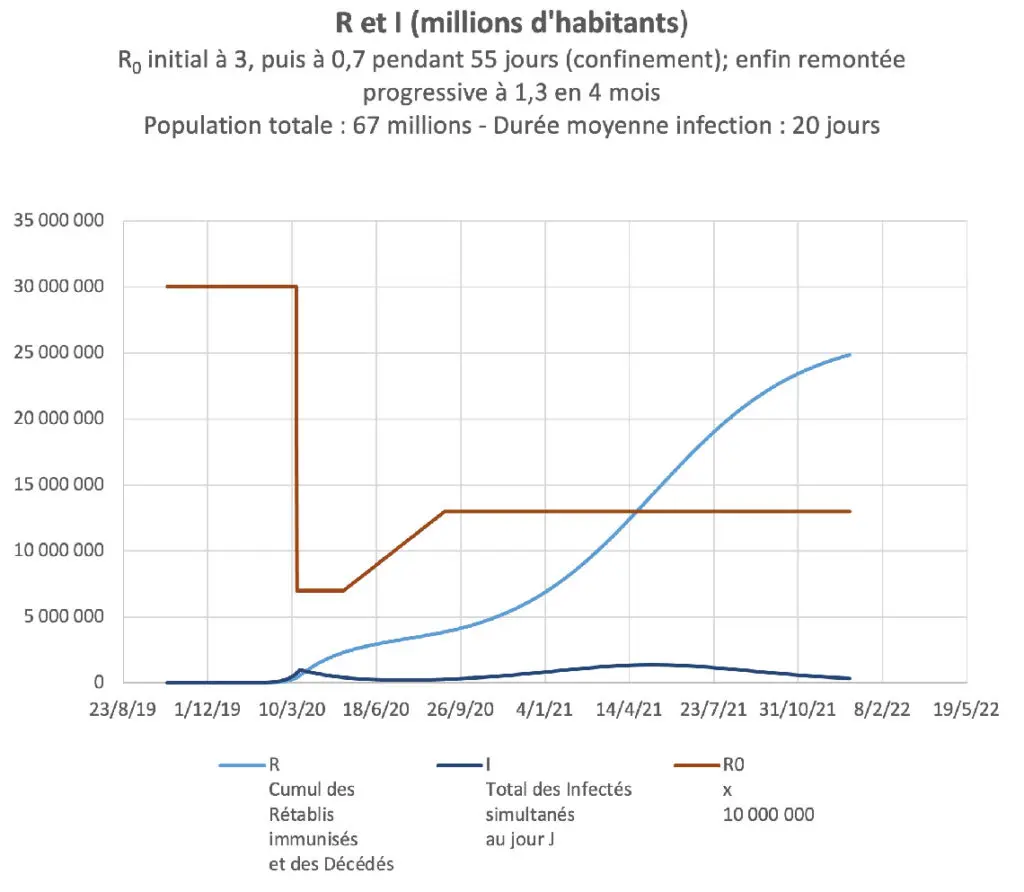
Le modèle SIR utilisant Excel montre que le nombre d’infectés simultanés qui avait augmenté jusqu’au début du confinement (mars 2020) décroît jusqu’à la fin juillet 2020. Ensuite, si le virus n’évolue pas, si R0 reste stable à 1,3 et si aucun nouveau traitement efficace n’est mis en œuvre, le nombre d‘infectés simultanés croît jusqu’à un maximum en juin 2021 (courbe bleu foncé) puis diminue jusqu’à ce que l’immunité collective correspondant à R0 = 1,3 soit atteinte (environ 40 % de la population immunisée suite à guérison ou à toute autre cause, voir plus bas), ce qui ne survient qu’en 2022.
À la mi-août 2020, le cumul de personnes qui ont été contaminées (courbe bleu clair) est d’environ 4 millions. Une létalité réelle de 0,5 à 1 % conduit à 20 à 40 000 décès depuis le début de la pandémie, fourchette compatible avec les chiffres observés en France.
Si les conditions rappelées plus haut restent inchangées, l’évolution ultérieure prévue par Excel correspond ensuite à une hausse sensible entre le creux de juillet 2020 et le printemps 2021 du nombre quotidien de nouveaux infectés. Toutefois cette hausse sera beaucoup moins rapide que celle de mars 2020 où le nombre de nouveaux contaminés et de décès doublait chaque semaine. On assistera ensuite à une lente décroissance jusqu’à extinction de l’épidémie début 2022 (à condition que R0 reste à 1,3 !). Mais plusieurs éléments sont susceptibles de modifier cette prévision : mutations imprévisibles du virus, disponibilité de traitements des malades réduisant la durée d’infection, arrivée de vaccins, sans oublier les réactions comportementales de la population, que ce soit par prise de conscience et initiatives individuelles (surtout chez les plus vulnérables) ou par respect de consignes indicatives ou coercitives des pouvoirs publics.
Létalités réelle et apparente
Le taux de létalité réel, ou infection facility rate (IFR), est le rapport entre le nombre de décès imputés à l’épidémie et le nombre total de personnes (y compris les asymptomatiques) qui ont été infectées par le virus correspondant. Pour des raisons pratiques, ce dernier nombre ne peut être qu’estimé, car il n’est pas mesurable : pour un pays comme la France, à raison de 100 000 tests par jour, il faudrait près de deux ans pour tester une seule fois toute la population.
Cette létalité dépend de caractéristiques du virus qui, dans le cas de la Covid-19, paraissent jusqu’à maintenant assez stables et assez semblables dans l’ensemble des pays touchés. Des différences entre pays et régions peuvent apparaître pour des raisons de fond (état de santé général de la population, qualité du système de soins) et des méthodes divergentes de saisie des motifs de décès, en particulier dans les cas fréquents de comorbidité. Au moment où cet article est écrit, l’estimation du taux de létalité réel de cette infection, au moins en France et dans des pays de niveau de développement comparable, semble être une fourchette allant de 0,5 à 1 %.
Le taux de létalité apparent, ou case facility rate (CFR), est le rapport entre le nombre de décès imputés à l’épidémie et le nombre de personnes qui ont été testées positives. La létalité apparente est donc totalement dépendante de la politique de tests qui varie énormément de pays à pays (par exemple aux États-Unis, on a longtemps testé beaucoup plus qu’en France). Lorsqu’ils sont fondés sur des « létalités » tout court qui sont en fait des létalités apparentes, les nombreux articles ou ouvrages qui prétendent comparer à partir de ce chiffre l’efficacité de différents systèmes de soins face à ce virus sont donc ineptes.
« La létalité n’a pas d’influence directe sur la propagation de l’épidémie. »
Dans un modèle épidémiologique, la létalité n’a pas d’influence directe sur la propagation de l’épidémie, puisque ce qui détermine cette dernière est la baisse progressive du nombre d’individus pouvant être contaminés, que les autres aient été immunisés par infection-guérison ou vaccination ou qu’ils n’aient pas survécu à l’infection.
Taux de contamination de la population apportant une immunité collective (herd immunity)
L’emploi d’Excel permet de déterminer facilement le taux d’immunité collective, c’est-à-dire le pourcentage de la population qui doit avoir été contaminé (ou vacciné) pour que l’épidémie s’arrête d’elle-même. Il suffit de prolonger le tableau contenant S, I et R jusqu’à ce que I devienne nul. La courbe R se termine par une droite horizontale donnant le taux d’infectés minimal dans la population pour que l’épidémie s’arrête.
On remarque que ce taux est très dépendant de R0. Une série d’essais Excel avec des R0 allant de 1 à 4 donne la courbe suivante.
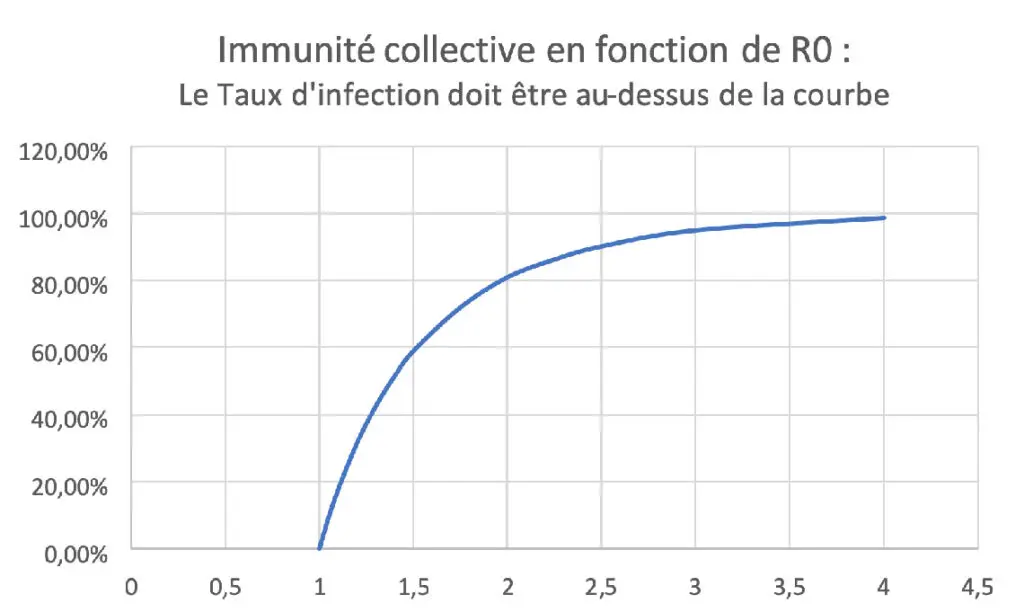
Les cours d’épidémiologie donnent pour cette courbe l’équation suivante :
Tauxcollective = 1 – exp ( – R0 x Tauxcollective )
qui confirme les résultats obtenus grâce à Excel, méthode qui ne demande aucune connaissance mathématique particulière.
Est donc inexacte l’affirmation que l’on entend ou lit souvent, selon laquelle pour atteindre une immunité collective il faut que le taux total de personnes ayant été infectées dépasse 60 ou 70 %. La courbe montre que, si une population réussit à maintenir de façon durable un R0 inférieur à 1,5, l’immunité collective est obtenue pour des valeurs inférieures à 60 % (par exemple environ 40 % pour un R0 de 1,3). La combinaison d’un R0 et d’un taux d’infection de la population permettant de se positionner au-dessus de la courbe permet aussi d’attendre l’arrivée d’un vaccin, d’un remède ou d’une éventuelle mutation favorable du virus. Il est possible que certaines zones à forte densité de population soient actuellement proches de cette immunité collective (Stockholm ?), mais s’y maintenir de façon durable impose de ne pas laisser augmenter le R0 qui aura permis d’en bénéficier.
Articles similaires :
 Modèles mathématiques d’épidémies les plus élaborés : pourquoi leurs prévisions initiales sont-elles souvent excessivement pessimistes ?
Modèles mathématiques d’épidémies les plus élaborés : pourquoi leurs prévisions initiales sont-elles souvent excessivement pessimistes ?
 SARS-CoV‑2 : « Où est caché le loup ? »
SARS-CoV‑2 : « Où est caché le loup ? »
 « Deuxième vague » Covid-19 : perspectives 2020–2021
« Deuxième vague » Covid-19 : perspectives 2020–2021
 Covid-19 : interrogations sur le modèle épidémiologique,
Covid-19 : interrogations sur le modèle épidémiologique, Prise en compte de la vaccination et du « variant anglais »
 Covid-19 : perspectives d’infection par le variant Omicron
Covid-19 : perspectives d’infection par le variant Omicron
9 Commentaires
Ajouter un commentaire
Merci, c’est très intéressant. Je me permets une remarque complémentaire : la difficulté c’est qu’on a des paramètres pour l’épidémie que sont très différents selon les classes d’âge, aussi bien en taux de létalité (par exemple près de 30% des hospitalisés de plus de 80 ans succombent, alors que l’on est nettement sous 1% pour les moins de 30 ans), qu’en taux de contamination (par exemple fin septembre la prévalence est de 200⁄100 000 hab sur les 15–44 ans et environ 50 chez les > 75 ans). En définitive, ce qui définit la courbe de mortalité sur le long terme, c’est surtout la façon dont les plus âgés se seront protégés, tandis que d’un pays à l’autre il faut aussi comparer les pyramides des âges.
Pendant l’unité de temps un individu infecté (donc faisant partie du compartiment I) a en moyenne κ contacts potentiellement contaminants avec un autre membre de la population, donc κ.S/N avec un individu susceptible d’être contaminé. Si τ est la proportion moyenne de ces contacts débouchant sur une contamination, il en contamine donc κ.τ. S/N. En moyenne, au bout d’un certain temps (sortie de confinement …) les plus âgés ont un κ.τ plus faible que les plus jeunes en raison d’un comportement plus prudent. On peut faire des estimations relatives à l’influence de l’âge sur la moyenne de κ.τ (et son évolution dans le temps) ce qui impacte β (= κ.τ/N ) et R0 (= κ.τ.D ). Le modèle Excel à β et R0 variables présenté permet donc la prise en compte de cette différence de comportement avec l’âge (qui fait plus que compenser une éventuelle propension supérieure à être contaminé lors d’une rencontre en raison d’un système immunitaire affaibli).
La différence de létalité entre jeunes et plus âgés n’a pas d’influence sur le développement de l’épidémie pour lequel on peut dire cyniquement qu’un décès a le même effet qu’une guérison immunisante : c’est de diminuer d’une unité le nombre d’individus susceptibles d’être contaminés.
Bravo ! Ton raisonnement est très clair.
Nul n’est censé persévérer dans l’erreur. Tu préconises page 7 de mieux déterminer le coefficient béta face à un nouveau virus. Mais pourquoi pas déjà avec le virus en cours ? L’impact sur l’économie des mesures « barrière », et a fortiori un futur confinement, sera catastrophique. Voir à ce sujet l’excellent livre de notre camarade Robert Boyer (X 62) sur les capitalismes à l’épreuve de la pandémie. Il insiste lourdement sur l’impact en fonction de la durée de la pandémie. C’est effectivement un des très grands risques.
Ce serait bien d’avoir ton fichier Excel.
Bel article.
L’immunité de groupe semble tomber à l’eau avec des réinfections à 6 mois, ce qui laisse planer des doutes sur l’efficacité magique d’un vaccin.
De même le nombre de cas dépend du nombre de personnes symptomatiques qui sont volontaires pour se faire tester. Ce qui nécessite d’être symptomatique (~50% ?) et volontaire pour un test (d’expérience quotidienne depuis 7 mois, à la louche 50%). Le virus est donc mal tracé et comme bien précisé, il s’infiltrera chez les plus fragiles.
Avec un hôpital toujours aussi mal géré et pourtant pléthorique.
Des mois de douleur en perspective.
A Jean-Baptiste. En fait j’ai fait une erreur de vocabulaire : j’ai écrit qu’on atteignait l’immunité de groupe lorsqu’il n’y avait plus du tout d’infectés, alors qu’habituellement ceci veut dire qu’on a atteint ce qui s« appelle Imax (maximum d’infectés simultanés), moment à partir duquel l’épidémie s’arrête d’elle-même.
Ceci ne veut pas dire qu’il n’y aura plus de nouvelles infections pendant cette période de décroissance, mais qu’elles seront en nombre insuffisant pour que l’épidémie perdure. Donc si le taux de perte de l’immunité après 6 mois n’est pas trop élevé, ceci n’empêchera pas l’épidémie de s’arrêter (tout au plus ça retardera la fin).
Le nombre de personnes infectées ou ayant été infectées est inconnu faute de tests dits aléatoires (par sondage sous la houlette d’organismes spécialisés, éventuellement en rétribuant des panels de sondés). C’est une grosse lacune dans le suivi de l’épidémie qui rend hasardeuses toutes les prévisions.
Merci, c’est très clair. Tout petit correctif, je pense qu’on parle d” Infection *Fatality* Rate (IFR) et de Case *Fatality* Rate (CFR)
Merci Patrick de cette correction.
J’ai rectifié un autre point dans un nouvel article qui va figurer dans la J&R de novembre et qui concerne l’immunité collective. J’ai inclus dans l’article d’octobre la courbe en fonction de R du total cumulé des infections depuis le début de l’épidémie jusqu’à sa disparition. Or traditionnellement la littérature sur ce sujet considère qu’on a atteint l’immunité collective non pas lorsque l’épidémie se termine mais dès qu’elle commence à diminuer. Le taux cumulé d’infections à ce moment ne tient donc pas compte de celles survenant pendant la phase de décroissance de l’épidémie. Je donne les 2 courbes dans l’article de novembre.
bonjour,
voilà je ne suis pas un grand utilisateur d “excel , par contre auriez vous une idée pour intégrer les paramètres complémentaires ci-dessous
a) impact potentiel de la vaccination en fonction de sa progression ( nombres de vaccinés prévus par semaine , )
b ) durée de la vaccination ” impact de la durée ” sur l’évolution (hypothèse exemple n vaccins par semaine)
c ) intégrer ou à moduler par la durée de vie de la protection ( en mois ou semaines estimation)
cordialement jean luc theroude
Tout d’abord vous avez les tableaux Excel (sans vaccination) dans un article du mois de novembre accessible à https://www.lajauneetlarouge.com/deuxieme-vague-covid-19-perspectives-2020–2021_modele_sir/ Ce tableau permet de calculer les flux entre 3 « compartiments » : S (Sains), I (Infectés) et R (Rétablis ou décédés !), les individus passant de S à I (où ils séjournent pendant la durée de leur infection) puis de I à R.
Si on vaccine, dans la modélisation la plus simple il faut ajouter chaque jour aux débits précédents un débit direct de vaccinés de S vers R, que vous pouvez moduler en fonction de votre politique de vaccination (en principe dans ces simulations il faut utiliser des pas d’une journée). Après si vous voulez raffiner vous pouvez ne les faire passer dans R que quelques jours après la vaccination (temps nécessaire pour qu’ils soient immunisés), les faire remonter de R dans S au bout de quelques mois (perte d’immunité après vaccination), etc. Le but est de vider le plus vite possible S car l’épidémie commence à s’éteindre quand Ro x S / N passe en-dessous de 1 (ce qui ne signifie pas qu’elle est terminée, l’extinction prend un certain temps)