L’acteur incontournable de l’IA pour la médecine de précision

En misant sur l’IA et une meilleure valorisation de la donnée médicale et biomédicale, Owkin aide les acteurs du monde pharmaceutique à optimiser la recherche thérapeutique en couvrant l’ensemble des maillons de cette chaîne de valeur. Jean-Philippe Vert (X92), directeur de la R&D de la start-up, nous en dit plus.
Qui est Owkin ?
Owkin est une entreprise qui a été créée en 2016 par Thomas Clozel, médecin oncologue, et Gilles Wainrib (X03), chercheur en intelligence artificielle, afin de trouver et développer de nouveaux médicaments permettant de traiter chaque patient en capitalisant sur l’IA.
Pour ce faire, les solutions conçues et développées par Owkin vont de la recherche de nouvelles cibles thérapeutiques à l’identification des patients qui répondront à un traitement, en passant par l’optimisation des essais cliniques.
Aujourd’hui, sur ces sujets et enjeux, nous travaillons avec de nombreuses entreprises pharmaceutiques et avons mis en place trois alliances stratégiques avec Sanofi, Bristol Myers Squibb (BMS) et MSD. En parallèle, nous développons également nos propres programmes de recherche thérapeutique.
À ce jour, Owkin a levé plus de 300 millions d’euros d’investisseurs pour poursuivre son développement. Nous employons 340 collaborateurs dans nos bureaux de Paris, Nantes, Londres, New York et Boston.
Revenons sur les enjeux et problématiques du monde pharmaceutique que vous adressez directement avec vos solutions. Pouvez-vous nous en dire ?
La recherche de médicaments est une entreprise coûteuse et risquée. 90% des nouveaux médicaments qui sont testés sur des humains dans des essais cliniques échouent, alors qu’on estime que le coût de la mise sur le marché d’un médicament à près de 3 milliards de dollars. En parallèle, un nombre significatif patients ne répondent pas aux traitements existants.
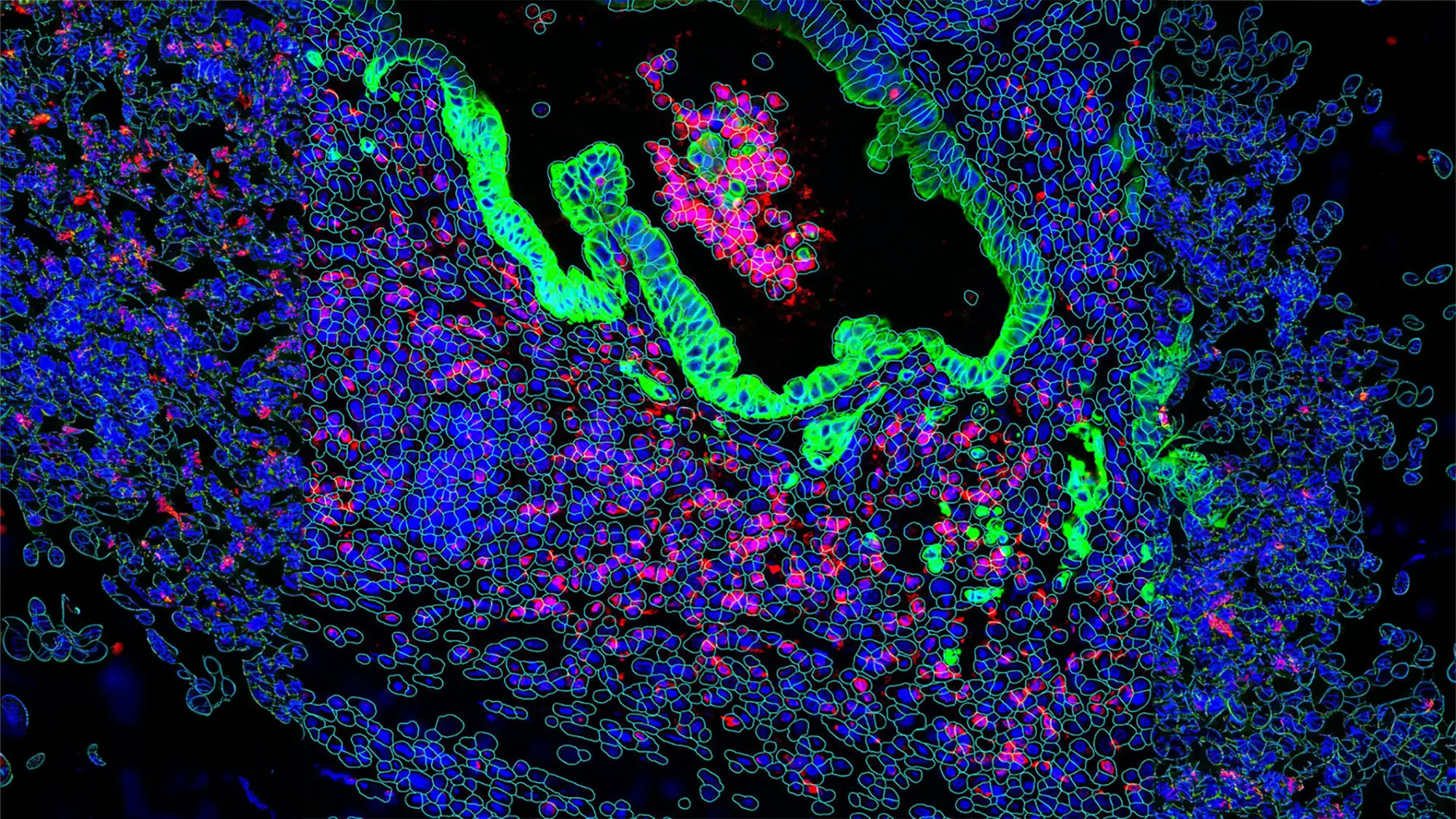
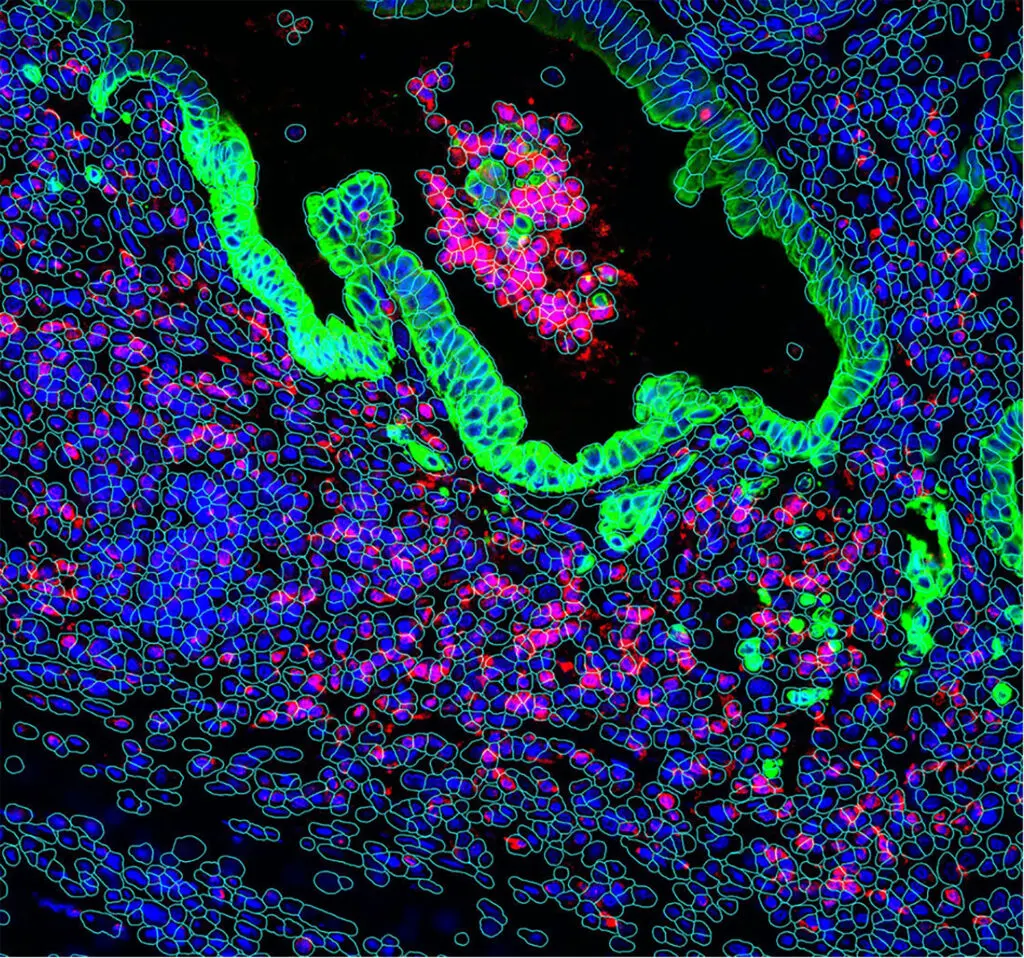
Cette situation s’explique par le fait que la recherche pharmaceutique traditionnelle s’appuie essentiellement sur des modèles dits pré-cliniques (lignées cellulaires cultivées dans des boîtes de Petri, animaux) qui échouent à refléter toute la complexité de la biologie chez les patients. Forts de ce constat, chez Owkin, nous avons fait le choix de partir directement des patients pour comprendre la maladie et identifier les traitements adaptés à chacun et non de ces modèles pré-cliniques. Pour ce faire, nous collectons de grandes quantités de données biomédicales, notamment des données génomiques caractérisant chaque tumeur au niveau moléculaire, ou de l’imagerie microscopique, et développons, à partir de là, des algorithmes d’IA pour analyser ces données et identifier des sous-populations de patients susceptibles de répondre à des traitements existants ou à développer.
Dans ce cadre, Owkin propose donc des solutions qui vont de l’identification de nouvelles cibles thérapeutiques au re-positionnement de traitement existants dans des populations cibles, que nous pouvons, par ailleurs, identifier grâce à nos propres outils de diagnostics développés en interne. Ces technologies permettent non seulement d’identifier de nouveaux traitements, mais également d’accélérer et de dé-risquer les essais cliniques en identifiant mieux les populations cibles.
Dans cette démarche, l’innovation et la technologie sont des enjeux clés. Qu’en est-il ? Plus spécifiquement, quelle place occupe l’IA ?
L’IA est au cœur de notre plateforme technologique. Nous appuyons aussi sur une équipe technique de près de 150 personnes pour explorer et déployer des solutions IA innovantes. Depuis la création d’Owkin, nous avons développé une expertise de pointe sur l’IA appliquée aux données biomédicales, notamment en génomique et en imagerie, que nous allons, par exemple, utiliser pour construire des modèles diagnostiques ou pronostiques afin d’identifier des patients susceptibles de répondre à un traitement donné.
Au-delà, nous publions régulièrement nos avancées scientifiques dans des revues et conférences scientifiques. En 2024, nous sommes lauréats du challenge Kaggle sur la classification de cancer de l’ovaire en sous-types à partir d’images anatomopathologiques. Nous sommes arrivés premier sur plus de 1 300 équipes participantes dans le monde.
Nous avons également une expertise unique en apprentissage fédéré, une technique d’IA permettant d’entraîner des modèles sur des données qui ne sont pas centralisées. En 2024, nous avons ainsi publié la première étude déployant cette technologie pour entraîner un modèle prédisant le risque de rechute dans les cancers du sein triple-négatifs. Dans ce cadre, nous avons entraîné un modèle sur les données d’un hôpital à Lyon et à Bordeaux, sans que les données ne quittent les serveurs des hôpitaux.
Revenons sur cette dimension d’entraînement de l’IA et de développement des modèles. Dans ce cadre, quelles données utilisez-vous ?
Nous entraînons nos modèles en partie sur des données disponibles publiquement, mais surtout sur des données multimodales auxquelles nous accédons à travers un réseau de plus de 50 hôpitaux avec qui nous travaillons, en Europe et en Amérique du Nord. Parmi ces établissements, on retrouve, par ailleurs, 8 des 20 meilleurs hôpitaux du monde en oncologie selon le classement Newsweek.
Nous avons une approche très collaborative et publions régulièrement les résultats de nos travaux avec les centres. En outre, nous apportons des solutions techniques pour garantir la sécurité et le respect de la protection des données, comme l’apprentissage fédéré que j’ai précédemment cité et qui donc permet d’entraîner des modèles d’IA sans avoir accès directement aux données utilisées.
Quelques mots sur vos principaux partenariats et les projets phares qui vous mobilisent actuellement.
Comme mentionné, nous avons trois partenaires pharmaceutiques stratégiques : Sanofi, avec qui nous travaillons sur des programmes de découverte de médicaments ; BMS, sur des questions de développement de médicaments (optimisation d’essais cliniques) ; et un nouveau partenariat signé en 2024 avec MSD pour le développement d’outils de diagnostic permettant d’identifier rapidement des patients susceptibles de répondre à leur médicament phare en oncologie.
Cette année, nous avons également lancé un projet phare de génération de données appelé MOSAIC (multi-omics spatial atlas in cancer), qui représente un investissement de 50 millions de dollars pour générer des cartes d’identité moléculaires de 7 000 patients atteints de cancer. Pour chacun d’entre eux, nous allons notamment générer une carte spatiale décrivant le niveau d’activité de plus de 20 000 gènes dans la tumeur en utilisant une technologie récente appelée la transcriptomique spatiale. Cette démarche va permettre de mieux comprendre les facteurs en jeu dans la réponse à l’immunothérapie.
En matière d’IA, nous lançons un nouveau projet phare pour construire un modèle de fondation de la biologie, une sorte de “chatGPT de la biologie”, pour automatiquement capturer la complexité du vivant en analysant des grandes quantités de données biomédicale. Concrètement, cela va permettre d’améliorer la performance de l’ensemble de nos modèles d’IA et, à terme, de formuler de nouvelles hypothèses biologiques automatiquement.
Quelles sont les prochaines étapes pour Owkin ? Comment vous projetez-vous sur le moyen et long terme ?
Au niveau du diagnostic, nous avons reçu en 2023 le marquage CE permettant de déployer notre premier modèle d’IA pour diagnostiquer une aberration génétique, l’instabilité de micro-satellite, qui augmente la probabilité de réponse à l’immunothérapie dans le cancer colorectal à partir d’image d’anatomopathologie. Nous allons maintenant commercialiser ce modèle, l’étendre à d’autres indications en partenariat avec MSD, et développer d’autres modèles diagnostiques.
En parallèle, nous continuons à avancer dans nos programmes de recherche interne, et envisageons de lancer une première molécule thérapeutique en essai clinique d’ici fin 2024. Sur le long terme, notre ambition est de nous positionner comme l’acteur incontournable de l’IA pour la médecine de précision.
Articles similaires :
 Focus sur l’extraction des métaux : enjeux et perspectives pour la santé
Focus sur l’extraction des métaux : enjeux et perspectives pour la santé
 La santé naturelle : un univers dynamique, innovant et aux multiples perspectives de croissance
La santé naturelle : un univers dynamique, innovant et aux multiples perspectives de croissance
 Ultra-compacts, ultra-fiables et ultra-performants : une révolution pour les implants médicaux
Ultra-compacts, ultra-fiables et ultra-performants : une révolution pour les implants médicaux
 Un investisseur à la croisée du monde de la biotech et du venture capital
Un investisseur à la croisée du monde de la biotech et du venture capital
 Le pionnier de la télésurveillance ophtalmologique en France
Le pionnier de la télésurveillance ophtalmologique en France