
Des algorithmes et des hommes, Applications de l’intelligence artificielle à la justice

La JR a rencontré le professeur Michalis Vazirgiannis, chef du DaSciM (Data Science and Mining Team) au LiX – École polytechnique : travaux pionniers pour l’application des techniques d’IA et de machine learning au domaine de la justice.
Notre équipe travaille à partir de l’idée que, avec les moyens de calcul et les bases de données dont on dispose maintenant, il est désormais possible d’extraire et d’exploiter des informations intéressantes de grands ensembles de données. C’est quelque chose qui avait été entrevu dès les années 90, avec un premier intérêt pour l’intelligence artificielle à l’époque, mais les moyens techniques n’étaient pas au rendez-vous. Maintenant, ils le sont, et on progresse vite.
J’ai rejoint l’X en 2013, venant d’Athènes où j’enseignais l’informatique à l’université d’Économie et d’Affaires. Nous avons démarré dans le cadre d’un projet financé par le réseau de recherche Digiteo de Saclay, et nous avons développé trois piliers pour notre activité.
En premier lieu, l’enseignement. Nous avons introduit ce domaine pour la première fois dans les enseignements du cycle ingénieur polytechnicien, autour de notions comme le Text Mining (extraction de texte) ou le NLP (traitement du langage naturel).
Ensuite, bien sûr la recherche. Nous travaillons sur l’apprentissage automatique (machine learning) sur des données à grande échelle, avec un intérêt particulier pour ce qui est textes et graphes. En effet, beaucoup de choses sont représentables par des graphes. Nous avons travaillé sur un nouveau concept de « graphes de mots », en mélangeant des documents sous formes de textes et de graphes.
Et enfin, des projets finalisés, car il faut bien financer toute notre recherche : nous avons ainsi obtenu 2 millions d’euros de financement industriel en cinq ans, avec notamment une chaire de « Data Science » portée par AXA, mais nous avons travaillé aussi avec Google, Microsoft, la FDJ…
“L’IA produit une cartographie
sociale de la pratique des avocats
et des juges”
C’est ainsi que j’en suis venu à m’intéresser à la smart law, c’est-à-dire les applications de l’intelligence artificielle au domaine de la justice. C’est un travail que nous avons entrepris avec David Restrepo, qui est professeur de droit à HEC. Il consiste à s’intéresser à l’extraction d’information utile à partir des données constituées par les décisions de justice du ressort de la cour d’appel de Paris. C’est la cour d’appel la plus importante de France, avec plus de 50 juridictions subordonnées (tribunaux de grande instance, tribunaux de commerce, prud’hommes, etc.) réparties sur six départements français. Elle produit un grand nombre de décisions de justice : nous travaillons actuellement sur une base de données de 12 000 textes, compilée par Dalloz. À terme, on devrait arriver à un million de textes.
Nous appliquons donc nos méthodes sur ces données-textes pour en tirer différents types d’informations.
Par exemple, nous travaillons sur le « réseau social » constitué par les juges et les avocats impliqués dans ces décisions (ils sont près de 3 000…). On peut ainsi cartographier ce réseau et y identifier des informations intéressantes : par exemple en faisant de la « détection de communautés » : quels sont les avocats qui se retrouvent le plus souvent dans les mêmes affaires, quels sont ceux qui gagnent le plus souvent, ou bien qui perdent le plus souvent, et contre qui, etc. L’IA produit ainsi une cartographie sociale de la pratique des avocats et des juges. On débouche sur un classement des avocats par type d’affaires traitées, ou par chance de succès. Le barreau de Paris est très intéressé par ces avancées.
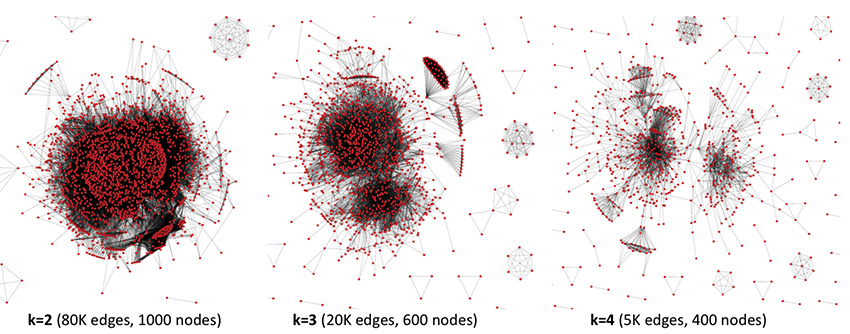
On peut travailler aussi, non plus sur les acteurs judiciaires et leurs réseaux, mais sur les affaires elles-mêmes. Les mêmes techniques permettent de visualiser comment les affaires traitées par la cour d’appel de Paris s’organisent autour de thèmes identifiés par les articles de loi auxquels il est fait référence dans les décisions. Les graphes reproduits ci-dessus représentent les 1 500 affaires traitées par la cour d’appel au dernier trimestre 2018. On voit que le niveau de structuration se précise quand on augmente le nombre d’articles de loi communs à plusieurs décisions que l’on retient comme paramètre de mise en relation de deux affaires (paramètre k = 2, 3, 4…) : pour k = 2 (c’est-à-dire quand on retient de mettre en relation les affaires qui impliquent 2 articles de loi identiques), le résultat reste très confus. Quand on passe à k = 3 puis 4, le graphe se structure progressivement. On fait ainsi apparaître des réseaux principaux et des sous-réseaux, et on identifie des thèmes autonomes, c’est-à-dire qui ne se connectent pas aux réseaux principaux, comme on le voit sur la figure. Ici, on identifie des groupes de décisions isolés portant par exemple sur les litiges au sujet des Airbnb, ou un autre relatif à des litiges concernant la SNCF… On accède ainsi à une appréhension globale du champ des décisions judiciaires. Tout cela peut contribuer à davantage d’accessibilité de ce champ pour les justiciables, et à davantage de transparence du système dans son ensemble.




